1 隐马尔科夫模型
隐马尔科夫模型(hidden Markov model,缩写为HMM)的提出最初是在语音处理领域。HMM是在Markov链的基础上发展起来的一种统计模型。由于实际问题比Markov链模型所描述的更为复杂,因此在HMM中观察到的事件与状态并不是一一对应,而是与每个状态的一组概率分布相联系。它是一个双重随机过程,其中之一是Markov链,描述状态的转移;另一个描述每个状态和观察值之间的统计对应关系。这样,HMM以概率模型描述观察值序列,具有很好的数学结构,能够比较完整地表达观察值序列的特征[5]。图1是一个离散HMM(D-HMM)的例子。
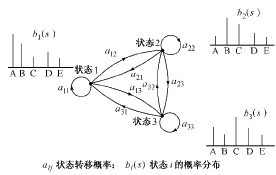
图1 离散隐马尔科夫模型
Fig.1 Discrete HMM
HMM可以记为:λ=(N,M,π,A,B),其中N为模型中Markov链状态数目;M为每个状态对应的可能的观察值数目;π为初始状态概率矢量;A为状态转移概率矩阵;B为观察值概率矩阵。
HMM的3个基本问题也已经有了比较理想的解决方案,即前向―后向算法、Viterbi算法和Baum―Welch算法(训练算法),同时提出了多观察值序列的训练算法、比例因子算法等改进方法,这为HMM的实际应用打下了坚实的基础。
2 用于涌流识别的观察值序列和训练序列
变压器内部故障时将产生高于额定电流几倍至十几倍的故障电流,基本的波形是一个含有衰减直流分量的交流正弦波。而变压器合闸时产生的励磁涌流在数值大小上接近甚至超过故障电流,两者在数值上不可区分。理论上的励磁涌流波形有明显的间断,但是由于检测电流互感器(TA)二次侧的饱和作用,涌流的间断部分将变得连续,使得间断角原理失效。尽管如此,涌流波形还是与故障波形有很大区别:涌流波形在过零处有畸变,正负半周不对称。这成为许多判据的基础。
这里,HMM的观察值序列就是变压器内部故障和励磁涌流采样数据。图2、图3是用EMTP仿真的波形。
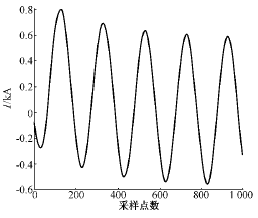
图2 变压器内部故障波形
Fig.2 Waveform of internal fault current
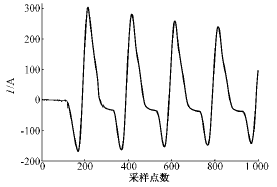
图3 变压器励磁涌流波形
Fig.3 Waveform of magnetizing inrush current
由于故障波形和涌流波形主要差别集中在负半周,因此HMM的训练序列采用归一化后波形的负半周。这样既可以突出两者的差别,也减少了计算量。图4、图5是两者归一化后一个负半周的波形。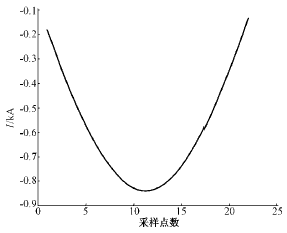
图4 故障波形的负半周
Fig.4 Negative half-cycle of fault current
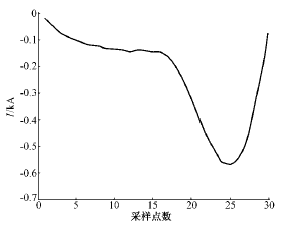
图5 涌流波形的负半周
Fig.5 Negative half-cycle of inrush current
为使得训练生成的模型能够充分反映两者波形的差别,这里将每一个负半周的采样序列作为一个训练序列,得到4个训练序列,应用多训练序列的算法进行训练。
3 离散HMM的应用
3.1 模型参数的选择
HMM最初是为语音信号处理提出的[6]。这里要处理的波形相对于语音信号而言要简单得多,因此HMM参数的选择就要相对简单,而且具有比较明确的物理含义。
由于每周期采样50点,负半周采样25点,因此首先将状态数目确定为N=25/2≈12。这样每个状态基本上对应于正弦波负半周上的均匀采样值,各状态的中心采样点的分布如图6所示。
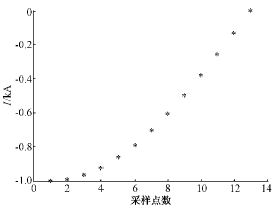
图6 离散HMM各状态的中心采样值
Fig.6 Center of each state of discrete HMM
每个状态的可能取值为所有上述均匀采样点加上0点,但中心采样点的概率占优。由此,M=N+1,B为N×(N+1)的矩阵,B矩阵的初值用以下方法确定:每个状态的中心采样点的概率最大,其前后3个点的概率依次减小,其余采样点的概率为0。如图7所示。
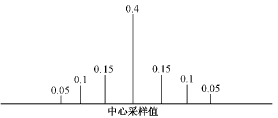
图7 B矩阵(行)初值
Fig.7 Initial value of matrix B(row)
对于A矩阵和π矩阵的初值则采用一般的均匀分布。对于状态驻留问题,由于考虑状态驻留时间的HMM的提出主要是为描述语音信号的短时平稳性,而不能采用状态驻留概率为负指数分布的一般HMM。但这里的两种信号的状态驻留基本上满足负指数分布,因此不需要应用考虑状态驻留时间的HMM。
3.2 模型的训练
这里采用的是多训练序列的HMM训练。多训练序列的训练公式为[5,6]:
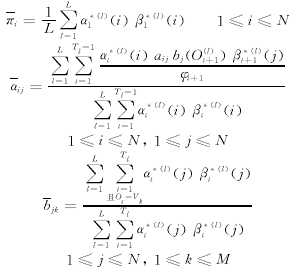
其中 α*(l)t,β*(l)t分别为第l个训练序列经过比例因子处理的前向、后向变量;N为状态数;M为每状态可能的观察值数,这里M=N+1;T为训练序列的数目;O为观察值序列;φ为比例因子序列;V即上述正弦波负半周的均匀采样序列。
需要说明的是在B矩阵参数的训练时,Ot=Vk将如下处理:当Vk≤Ot≤Vk+1时,判为Ot=Vk。
本文关键字:变压器 电工文摘,电工技术 - 电工文摘






