苹果iPhone 5S的发布将ARMv8指令集架构再一次带入媒体聚光灯下,初步测试结果显示苹果A7 SOC内部基于ARMv8指令集设计的Cyclone核心性能不凡,考虑到安卓阵营的旗舰机型已经开始配备2GB甚至3GB的内存容量,触及32bit的寻址能力瓶颈相信已经不远,而安卓阵营里具备CPU设计实力的公司寥寥无几,若向64bit的指令集架构迁移,可以预见大多数厂商仍会考虑Cortex-A50系列架构,本文将尝试窥探Cortex-A50系列的微架构设计。

指令集架构变化的影响
相对上一代32位指令集,ARMv8引入了许多调整,其中包括在64位环境下运行虚拟机中的32位操作系统等服务器级别的特性,能够与C++11等新兴编程语言匹配的弱内存模型等,我们在此前的文章中也分析了64bit环境下的寄存器数量与访存操作对性能带来的影响,抛开这些部分不谈,ARMv8的改变仍有两个有趣的地方。
第一是SIMD,128bit位宽的SIMD寄存器数量增长至32个,能够进行以64bit为粒度的重新切分,将一个128bit寄存器视为两个64bit寄存器,引入了双精度浮点,并且终于与经典的IEEE 754标准完全兼容,程序员们将能够看到规整的舍入模式,非规格数与NaN的处理,这项改进终于补上了先前指令集架构上对浮点支持孱弱的缺点。利用SIMD层面的进步,ARMv8将开始提供AES,SHA-1,SHA-256加密算法的指令级支持,未来的嵌入式安全领域有了进一步的性能保障。加速效果尚缺乏测试数据的证实,抛开加速效果不谈,仅从覆盖面上看,Cortex-A50相比支持广谱加密算法加速的SILvermont架构服务器SKU仍有较大差距,可以说ARM在这方面的脚步仍旧落后于Intel。
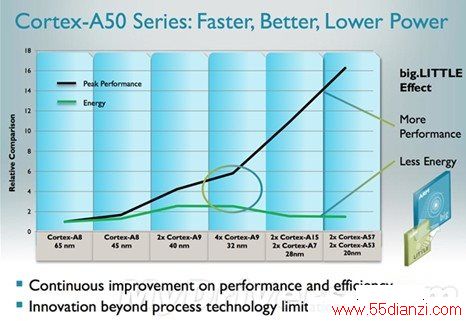
Cortex-A系列发展历史趋势:A50高性能、低功耗齐头并进
其次是谓词执行。由于分支指令在指令流中大致占据20%左右的比重,硬件上要进行准确的分支预测,需要维护巨大的辅助记录表,保存分支指令的历史走向,作为预测未来走向的参考。谓词执行的理念是,让指令携带谓词标志,指令执行&结果写回阶段时可以根据谓词标志位来判断指令是否需要被执行&结果写回,这种做法将消除大量难以预测的复杂分支,因此曾被寄予厚望。目前NVIDIA GPGPU就是使用谓词执行来控制分支,而ARM则激进的多,它的整套指令集几乎全部支持谓词执行,这在很久以来被视为ARM的一大特色,这种做法表明ARM曾经抱有这样的期待:分支预测器在嵌入式处理器的紧张面积、功耗预算下难以给出较高的预测准确率,而谓词执行有望弥补分支预测的缺憾。而随着时间推移,我们所看到的事实是,ARM在Cortex-A15等微架构的设计中,开始逐渐引入桌面处理器微架构里使用的分支预测器基本框架,并且ARMv8指令集也一改以往作风,大幅削减谓词执行,现在只剩下寥寥少数指令支持谓词化。这表明ARM已经开始逐渐倾向于使用复杂的分支预测器来处理分支,而谓词执行已经被边缘化。除此以外,由于每条指令执行与否都要访问谓词寄存器,因此在寄存器重命名阶段,每条谓词指令都要多占一个物理寄存器,这是一份额外的开销,也是ARM取消谓词执行的另一个原因。谓词执行在分支指令上的理论优势能否转化为实际优势,又能否弥补开销,是一个值得关注的问题,ARM内部对此应该做过量化分析,可惜结果没有发表。但从ARMv8大规模裁剪谓词执行的状况看,笔者推测量化评估的结果是比较负面的。
www.55dianzi.comCortex-A57与Cortex-A53
Cortex-A50系列的ARMv8处理器目前提供两种版本,按照big.Little策略被分为高性能高功耗的Cortex-A57与低性能低功耗的Cortex-A53。
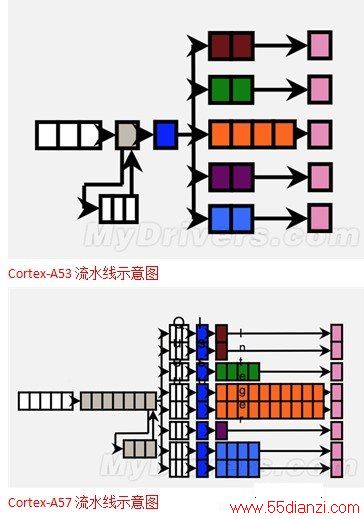
依据ARM放出的PPT上的图示,Cortex-A57的架构与Cortex-A15几乎如出一辙,乱序三发射15级流水线,而Cortex-A53也与Cortex-A7相似,顺序发射8级流水线。ARM并未透露这里的顺序发射宽度,笔者猜测应该是与Cortex-A7相同,使用顺序双发射。因此从流水线的框架上来说,Cortex-A57 = Cortex-A15 + 64bit,而Cortex-A53= Cortex-A7 + 64bit。

ARM将Cortex-A57和Cortex-A53分别比喻成哥哥和弟弟的关系
将同样的微架构设计迁移到64bit上并非如想象中那么容易,举例来说,有人认为Cortex-A15的指令读取带宽为每周期16字节,若把它搬到64bit指令集上,流水线前端将承受更大压力,这是一个设计缺陷吗?一条64bit指令占据8个字节,在不考虑Thumb指令集的情况下,Cortex-A57上每周期进入指令解码阶段的指令仅有2条,而指令解码阶段的设计宽度是每周期三条指令,加上分支预测的影响,指令读取阶段的效率的确可能将会冲击到CPU性能。但若我们回头看看以往的三发射微架构,也有一些使用16字节读取带宽的例子,例如Intel的P6,AMD的K8等,P6并不支持64bit,而AMD公开发表的数据表明,K8在32位模式和64位模式下的平均解码停顿非但没有增加,反而降低了10%,更有意思的是,最极端的测试代码在64bit下的解码停顿恶化了40%之多,但最终性能却反超32bit模式30%以上 —— 这意味着指令读取带宽并非关键问题所在。微架构设计时经常需要对这些细节进行量化分析以辨认、改进瓶颈,我们没有理由相信ARM是异类。在64bit如何保持同样的执行宽度在ARM内部一定做过量化分析,与此相似,苹果Cyclone核心在64bit模式下运行的性能冲击也一定做过类似的评估,只是这两家公司并不如AMD和Intel开放,因此具体细节我们无从获知。
依据ARM公开发表的结果,Cortex-A57的SPEC 2006得分大约在1200上下,超越Cortex-A9大约20%~30%左右,作为对照,一代英豪Core2 E6300的SPEC 2006成绩大约为2000左右,我们正在目睹嵌入式微处理器重复着桌面高性能微处理器的发展道路,在结构设计和最终性能上都逐步向着以Core为代表的高性能微架构靠拢。值得一提的是,SPEC单线程得分仅能衡量毫无干扰的理想环境下运行一部分单线程程序的能力,而在当下的多核计算条件下,处理器通常情况下将同时处理多个行为模式完全不同的线程,这些相互之间区别较大的线程将会在多核处理器上争抢缓存容量,缓存带宽等各种执行资源,导致性能不同程度地衰退,因此目前的SPEC得分距离实际应用环境下的真实体验仍有一段距离,因此SPEC在专业评估上也仅仅是参考标准之一。未来的体系结构中将加入关键程序的性能隔离,保障多核计算的混合环境下关键程序性能不会大幅衰退,目前已有不少相关的前沿研究正在展开。至于Cortex-A53,ARM声称它将达到Cortex-A9级别的性能,但是功耗仅有四分之一,面积仅有Cortex-A9的六成左右,A50系列的这两款产品把ARM阵营的路线图从28nm延伸了两代,覆盖20nm抵达14nm,届时ARM是否还会有新动作,颇为惹人好奇。
结语 未来移动计算市场的必争之地
向64bit进行的布局是一种超前于市场需要的战略举动,随着移动计算设备的持续进化,与桌面一样经历从32位到64位的跨越只是时间问题,ARM与Intel对此都早早进行了布局,64bit将成为未来争夺移动计算市场的阵地之一,引入64bit会不会需要操作系统与编译器的支持,以及开发者社区的跟进,这些生态系统层面的因素甚至比芯片本身的表现更加重要,甚至可能触发行业洗牌。Intel与ARM在这一轮中将如何表现,我们拭目以待。
本文关键字:暂无联系方式电子知识,电子学习 - 基础知识 - 电子知识






