算术编码 是一种无失真的编码方法,能有效地压缩信源冗余度,属于熵编码的一种。算术编码的一个重要特点就是可以按分数比特逼近信源熵,突破了HafFMan 编码每个符号只不过能按整数个比特逼近信源熵的限制。对信源进行算术编码,往往需要两个过程,第一个过程是建立信源概率表,第二个过程是对信源发出的符号序列进行扫描编码。而 自适应 算术编码在对符号序列进行扫描的过程中,可一次完成上述两个过程,即根据恰当的概率估计模型和当前符号序列中各符号出现的频率,自适应地调整各符号的概率估计值,同时完成编码。尽管从编码效率上看不如已知概率表的情况,但正是由于自适应算术编码具有实时性好、灵活性高、适应性强等特点,在图像压缩、视频图像编码等领域都得到了广泛的应用。
现场可编程门阵列( FPGA )是一种新兴的可编程逻辑器件,具有更高的密度、更快的工作速度和更大的编程灵活性,被广泛应用于各种电子类产品中。而硬件描述语言(HDL)是一种快速的电路设计工具,其功能涵盖了电路描述、电路合成、电路仿真等的三大电路设计工作。VHDL 是HDL 的一种,因其简单易懂而被广泛使用。本文采用VHDL 编程实现了自适应算术编码,为算术编码器的硬件实现提供了借鉴。
1 算术编码的基本原则
实现算术编码首先需要知道信源发出每个符号的概率大小,然后再扫描符号序列,依次分割相应的区间,最终得到符号序列所对应的码字。整个编码需要两个过程,即概率模型建立过程和扫描编码过程。
算术编码的基本原理是:根据信源可能发现的不同符号序列的概率,把[0,1]区间划分为互不重叠的子区间,子区间的宽度恰好是各符号序列的概率。这样信源发出的不同符号序列将与各子区间一一对应,因此每个子区间内的任意一个实数都可以用来表示对应的符号序列,这个数就是该符号序列所对应的码字。显然,一串符号序列发生的概率越大,对应的子区间就越宽,要表达它所用的比特数就减少,因而相应的码字就越短。
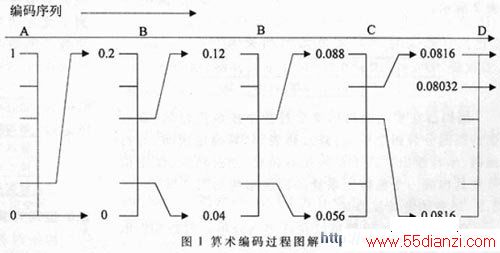
图1 给出一个实现算术编码的示例。要编码的是一个来自四符号信源{A,B,C,D}的由五个符号组成的符号序列:ABBCD。假设已知各信源符号的概率分别为:P(A)=0.2,P(B)=0.4,P(C)=0.2,P(D)=0.2。编码时,首先根据各个信源符号的概率将区间[0,1]。分成四个子区间。符号A 对应[0,0.2],符号B 对应[0.2,0.6],符号C 对应[0.6,0.8],符号D 对应[0.8,1.0]。符号序列中第一个符号是A,其对应的区间为[0,0.2],接下来将这个区间扩展为整个高度,再根据各个信源符号的概率将这个间扩展为整个高度,再根据各个信源符号的概率将这个新区间分成四段;第二个符号是B,它对应新的子区间的第二个子区间,即对应区间[0.04,0.12];再将该区间扩展为整个高度,再根据这个过程直接最后一个符号得到一个区间[0.08032,0.0816],这样该区间内的任何一个实数就可以表示整个符号序列,如0.081。
2 自适应算术编码的基本原理
自适应算术编码在一次扫描中可完成两个过程,即概率模型建立过来和扫描编码过程。自适应算术编码在扫描符号序列前并不知道各符号的统计概率,这时假定每个符号的概率相等,并平均分配区间[0,1]。然后在扫描符号序列的过程中不断调整各个符号的概率。同样假定要编码的是一个来自四符号信源{A,B,C,D}的五个符号组成的符号序列:ABBCD。编码开始前首先将区间[0,1]等分为四个子区间,分别对应A,B,C,D 四个符号。扫描符号序列,第一个符号是A,对应区间为[0,0.25],然后改变各个符号的统计概率,符号A 的概率为2/5,符号B 的概率为1/5,符号C 的概率为1/5,符号D 的概率为1/5,再将区间[0,0.25]等分为五份,A 占两份,其余各占一份。接下来对第二个符号B 进行编码,对应的区间为[0.1,0.15],再重复前面的概率调整和区间划分过程。具体的概率调整见表1。
表1 自适应算术编码的概率调整概率
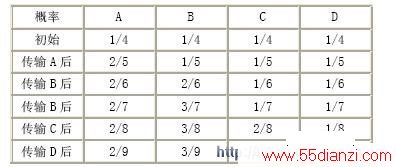
随着符号序列中符号个数的不断增多,自由适应算术编码估计得到的各符号的概率将趋于各符号的真实概率。
www.55dianzi.com
3 自适应 算术编码 的 FPGA 实现
3.1 总体设计
在利用FPGA 实现自适应算术编码的过程中,首先遇到的问题就是将浮点运算转化为定点运算,即将[0,1]区间的一个小数映射为一个便于硬件实现的定点数。考虑到硬件实现的简便性,本文中将[0,1]之间的浮点数与[0,256]之间的定点数对应。相应的对应关系如表2 所示。
表2 浮点与定点之间的关系浮点

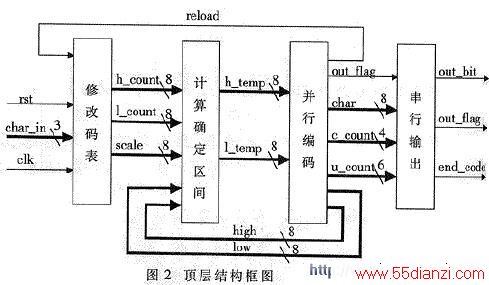
编码器在实现编码的整个过程中按照耦合弱、聚合强的原则分为四个模块:修改码表、计算确定区间、并行编码、串行输出。四个模块相对独立,通过输入、输出信号使其构成一个整体。系统的顶层结构如图2 所示。
&nb sp; 3.2 码表的设计及修改
自适应算术编码器可以在许多场合中得到应用。本文实现的自适应算术编码器应用在采用6符号对小波变换系数进行零树编码的小波域视频编码中[3],因此设计的码表中含有六个符号。这样根据自适应算术编码的基本原理,将区间分成六个子区间,整个区间含水量有七个分割点。所以码表可以用七个8 位寄存器表示。初始时设定等概率,这时七个寄存器可以顺序地存储0 到6 这七个数,即每个子区间的数值为1。随着符号不断地输入,自适应地修改码表,并且在修改码表的过程中时刻要保持寄存器中的数值是递增的。
修改码表时,首先判断输入符号,确定其所在区间,同时为后续模块输出该子区间的两个端点值l_count 和h_count 以及码表的最后一个端点值scale,然后进行码表的修改:将当前符号所在区间之后的所有端点值都加1,即当前区间及后面所有子我间的h_count=h_count+1,这样即完成了码表的修改。在数值不断累加过程中,寄存器中的数值为255 时,需要对每一个寄存器中的值都取半,并同时对相邻的两个寄存器中的值进行比较,时刻保持数值是递值的。这样,处理前后的概率十分接近,对压缩比影响不大。
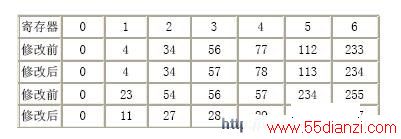
修改码表模块在输出h_count、l_count 和scale 之后,后面的计算子区间的模块即可进行计算;而修改码表模块在输出h_count、l_count 和scale 之后,亦可进行码表的修改。因此,这两个操作可以采用并行处理的方法实现,极大地节省了所用的时钟周期,相应地提高了速度,达到了优化的目的。表3 给出了输入符号为3(对应于寄存器2 与寄存器3 之间的区间)时码表的修改过程。
表3 码表修改前后对照表寄存器
3.3 区间计算及确定
初始时符号所在的总区间为high=0xff,low=0(high 和low 分别表示已编码的符号序列所在子区间的上下界)。随着符号的不断输入,high 和low 的值也不断地减小,用以表示输入符号序列所对应的子区间。通过如下的公式可确定输入符号的区间:

计算时,最耗资源的是乘法器和除法器。本方案中乘法器采用参数化模块lpm 中的lpm_mult生成。而除法器则自动编写。虽然占用的时钟周期较多,但与使用lpm 相比,这样做可以大大地提高工作频率,从总体上提高性能。
本文关键字:暂无联系方式DSP/FPGA技术,单片机-工控设备 - DSP/FPGA技术






