可配置处理器标志着第四代 微处理器 设计的开始,这种技术更加适合片上系统SOC的设计。每一代处理器持续大约十年时间,每个时代的处理器适合当时那个时期的需要。大约在二十世纪七十年代出现了第一代处理器,这个时期的处理器设计只是简单地追求性能,从4位处理器到早期的16位和32位微处理器。这种性能的提升奠定了二十世纪八十年代个人计算机PC和工作站的基础。个人计算机和工作站的增长使得微处理器设计进入了二十世纪八十年代的第二代微处理器研制时期。精简指令集RISC设计时代发生在二十世纪九十年代。在这个时期,即使像X86这样坚定的复杂指令集CISC处理器也假装成精简指令集RISC体系结构。在最初的这三代处理器的成长和发展过程中,微处理器设计专家将处理器设计成固定的、单个的和可重用的模块。但是,在二十世纪九十年代随着专用集成电路ASIC和片上系统SOC制造技术的发展为微处理器设计进入第四代(即后RISC、可配置处理器)打下了坚实的基础。
当今的系统开发工具已经非常先进,完全可以允许设计人员根据具体的应用目标任务来定制微处理器核。处理器定制可以在非常短的时间内,甚至是几分钟就可以根据具体应用完成片 上系统处理器核的设计。由于根据具体任务来定制处理器的速度非常快,因此可配置处理器可以具有非常优异的高性能来构建片上系统的设计,并且经常用于快速建立一些功能模块,而这些功能模块如果采用人工RTL方式设计的话,则可能需要几个月的时间。正是由于可配置处理器技术的高性能和快速开发能力,使得许多最终产品在多个可配置处理器核的基础上实现了片上系统SOC(多处理器片上系统SOC或者简写为 MPSOC )。这些最终产品的范围从最大和最小的网络路由器一直到诸如便携式摄像机、打印机和低成本视频游戏机等消费类电子产品。
两种最新的开发技术已经嵌入到可配置处理器甚至片上系统SOC设计中,即全自动化的、专用指令集定制技术和对处理器内部执行部件的 多口访问技术 。前者允许片上系统设计人员更加专注系统体系结构方面的问题,而通过依赖自动化设计工具来完成某些单一功能模块以达到性能方面的目标。后者则永远克服了以前那种存在已久的总线瓶颈问题,而这种总线瓶颈问题从1971年第一个微处理器出现以来就一直阻碍微处理器性能的提高。
自动化处理器定制
十多年来,硬件设计人员一直在努力用C或者C++对系统进行描述进而转换成有效的硬件。最初的系统说明通常是用C或者C++写成的,因为采用这些高级语言描述的系统可以在廉价的PC上进行执行和评价。然而,即使是廉价的PC也不适合许多嵌入式系统的设计,尤其是在消费电子领域,因为其功耗太大。因此,设计人员开始希望找到一种工具来将用C或者C++写成的系统描述转换成硬件。
许多像“行为综合”、“C语言硬件综合”和“ESL”等词汇描述的设计方法都有一些缺陷,因为它们都是试图解决在本质上很复杂的问题:用时序可执行语言写成的系统描述转换成并行互操作和非可编程的硬件模块。
TenSILica的XPRES编译器采用一种更加简单、更加直接的方法来解决这一设计问题。XPRES编译器不是试图从头开始进行与应用相关的硬件设计,而是从一个完整的功能处理器核开始设计,然后以添加硬件执行部件和相应的机器指令的方式来增加硬件,以加速处理器上目标应用程序的执行速度。因此,XPRES编译器从一个正在工作的硬件(Xtensa微处理器核)开始设计,同时使得目标程序代码运行得更快。这种搜索的结果是完成一个微处理器的配置,此配置有一个性能/硬件开销的特性曲线,如图1所示。

图1: XPRES编译器为设计者提供一系列微处理器配置。随着硅片面积的增加也使得与应用相关的系统性能得到提升。
性能优化的三种技术途径
XPRES编译器采用三种技术来建立优化的Xtensa处理器配置:操作数融合、单指令流多数据流SIMD(向量化)和FLIX(可变长度指令扩展)。操作数融合技术记录程序循环语句中简单操作出现的频度。XPRES编译器将这些指令序列合并成一条增强型指令,这种增强型指令通过减少循环内部的指令条数来加速程序代码的执行。图2表示由XPRES编译器产生的数据流操作,图中用灰色表示出融合操作。
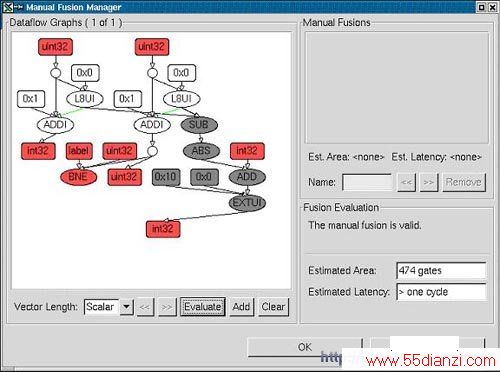
图2:由XPRES编译器产生的数据流图表示出一系列融合操作。当减法操作、取绝对值操作、加法操作和位域抽取操作融合成一条新的指令后,由XPRES编译器进行评估需要增加474个逻辑门。
应用程序中的许多循环语句对一个数据阵列执行相同的操作,XPRES编译器可以将这些循环语句进行向量化,建立一条由多个相同执行部件并行执行多个数据项的指令。对Xtensa处理器增加单指令流多数据流SIMD指令与Tensilica的XCC C/C++编译器是一致的,该编译器能够将应用程序代码中的内循环展开并且进行向量化。通过向量化可以加速循环语句的执行,这通常和增强型指令内部SIMD运算部件的序号有关。
www.55dianzi.com
XPRES编译器采用的第三种加速程序代码执行的技术是TenSILICa的FLIX(可变长度指令扩展)技术。FLIX指令是一种类似于融合和单指令流多数据流SIMD指令的多操作指令。然而,FLIX指令包括多个独立的操作,而融合和单指令流多数据流SIMD指令则均为相关多操作。FLIX指令中的每一个操作都是和其它操作互相独立的,XCC C/C++编译器将彼此独立的操作压缩成一条FLIX格式的指令,而这种压缩后的指令能够显著加速程序代码的执行速度。
采用可配置处理器进行多处理器SOC设计
在当今的应用中,很少只用一个处理器就能满足系统的性能指标,即使采用面向目标应用的可配置处理器也很难做到。然而,多处理器MP指令集、高带宽接口和小面积使得在一个片上系统SOC设计中可以集成多个可配置处理器。
片上系统SOC中处理器模块之间硬件互连机制的选择对系统性能和硅片成本产生很大影响,而且这些硬件互连机制必须直接支持多处理器MP系统设计的互连要求。消息传递软件通信机制直接影响到数据队 列。类似地,共享存储器软件通信模式也影响到基于总线的硬件系统。可配置处理器可以提供系统以很大的灵活性,提供对共享设备和存储器进行访问所需的仲裁机制。共享存储器总线的基本拓扑结构有如下几种:
1. 通过通用处理器总线访问系统全局存储器: 微处理器 设计一个通用接口以便实现多种总线事务处理。在读操作时,如果处理器认为相应的数据不在本地局部存储器(根据地址或者高速缓存CACHE缺失进行判断),那么处理器必须要进行全局存储器访问。处理器请求总线控制权,当控制权得到应答后,处理器通过总线发送读操作的目标地址。相应的设备(例如,存储器或者输入/输出接口)对地址进行译码,然后通过总线对处理器所需要的数据进行传送,如图3所示。
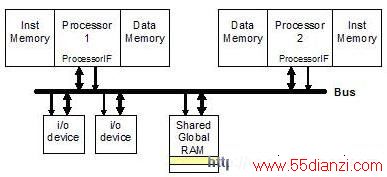
图 3: 两个处理器通过总线共享存储器
当两个处理器通过总线对全局共享存储器进行访问时,一个处理器获得总线控制权对数据进行写操作,另一个处理器就必须稍后才能获得总线控制权以便进行读操作。按照这种方式,每个字传输需要两个总线操作事务周期才能完成。该方法需要适度的硬件支持,并且具有较高的灵活性,因为全局存储器和输入/输出接口通过公共总线进行访问。然而,对全局存储器的使用却不好根据处理器和设备的数量进行度量,因为总线拥塞会使得访问时间变长和不可预测。
2. 通过通用处理器总线对处理器本地局部存储器进行访问:可配置处理器可以允许局部数据存储器参与通用总线事务处理。这些处理器基本上是由本地的处理器使用,并且二者是紧密耦合的。然而,控制局部数据存储器的处理器可以按照总线从设备的方式进行操作,如图4所示。
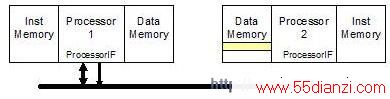
图4: 一个处理器通过总线访问第二个处理器的局部数据存储器
第一个处理器和第二个处理器之间访问时间的不对称性可以保证push 通信,即当第一个处理器向第二个处理器发送数据时,它将数据通过总线写到第二个处理器的本地局部存储器。如果写操作经过缓冲器,那么第一个处理器不必等到写操作完成就可以继续执行后面的操作。因此,到第二个处理器数据传输的长时间延时就被隐藏了。
3. 通过局部总线访问多口局部存储器:当数据流在处理器之间双向传输且对时延要求比较严格时,那么对任务间通信而言,采用本地共享数据存储器通常是最好的选择。每个处理器使用自己的本地数据存储器接口来访问共享存储器,如图5所示。存储器可以有两个物理访问端口(每个时钟周期可以访问两次存储器),或者通过一个简单的仲裁器来控制。
本文关键字:微处理器 DSP/FPGA技术,单片机-工控设备 - DSP/FPGA技术






