RS理论的缺点是:容错能力与泛化能力相对软弱,且只能处理量化数据等问题,而这恰好是SVM算法的长处。SVM实现了SRM原则,它最小化泛化误差的上界,而不是最小化训练误差,这就保证了SVM具有更好的泛化性能。SVM算法与神经网络方法相比有更少的自由参数。在SVM算法中,仅有三个自由参数。然而,神经网络却有大量的自由参数,需要凭经验主观选择。神经网络不一定能收敛到全局最优解,容易陷入局部最优解。而在SVM算法中,训练SVM就等价于解一个具有线性约束的二次凸规划问题,因而它的解是唯一的、全局的和最优的。
SVM的缺点是:不能确定数据中哪些知识是冗余的,哪些是有用的,哪些作用大,哪些作用小,而这正是RS理论的长处。
考虑到经典的SVM算法是建立在二次规划的基础上,对大数据量的模式分类和时间序列预测等问题,如何提高它的数据处理的实时性,缩短样本的训练时间,仍是亟待解决的问题。针对上述弱点,再结合RS理论与SVM算法各自的优缺点,本文提出一种将RS理论方法与SVM相结合的方法。利用RS理论在处理大数据量,消除冗余信息等方面的优势,减少SVM训练数据,克服SVM算法因为数据量太大而导致处理速度慢等缺点。将RS作为前置系统,再根据RS方法预处理后的信息结构,构成SVM数据预测系统。
2 基于RS预处理的SVM预测系统
从前面分析的RS理论方法和SVM方法各自的特点中,可以发现它们存在两个互补性的差别。(1)SVM处理信息一般不能将输入信息空间维数简化,所以当输入信息空间维数较大时,就会导致SVM训练时间较长,而RS理论方法却能够通过发现数据间的关系,既可以去掉数据中的冗余信息,又可以简化输入信息的数据空间的维数。(2)RS方法在实际应用过程中对噪声比较敏感,因而用无噪声的训练样本学习推理的结果在有噪声的环境中应用效果就不太好,也就是说RS方法的泛化性能较差,而SVM方法有较好的抑制噪声干扰的能力,且具有良好的泛化能力。因而根据它们的互补性把两者结合起来,用RS先对数据进行预处理,即先把RS网络作为前置系统,再根据RS预处理后的信息结构,来构成SVM的信息预测系统。这种系统具备以下几个明显的优点:
(1)利用RS方法减少信息表达的特征数量,使SVM输入端数据数量大大减少,提高了系统的速度。
(2)利用RS方法去掉冗余信息后,简化了训练样本集,也减少了系统的训练时间。
(3)把SVM作为后置的信息处理系统,具有容错和抗干扰的能力。
一种基于RS预处理与SVM相结合的预测系统框图如1所示。

训练样本集首先从收集的原始数据中产生,然后将条件属性值进行量化。量化后的属性值形成一张二维表格,每一行描述一个对象,每一列描述对象的一种属性,属性分条件属性和决策属性。决策表约简包括条件属性简化和决策规则简化。条件属性简化,即去掉某一属性后,考察决策表的相容性,如果去掉该属性后决策表是相容的,就去掉该属性,直到决策表最简为止。决策规则简化就是在条件属性简化后的决策表中,去掉样本集中的重复信息,考察剩下的训练集,每一条规则中哪些属性值是冗余的,去掉冗余信息和重复信息后,就得到最小决策算法。也可以先简化每一决策规则,再简化条件属性,从而得到最小条件属性集。采用约简得到的最小条件属性集及相应的原始数据重新形成新的训练样本集,该样本集除去了所有不必要的条件属性,仅保留了影响预测精度的重要属性。用约简后形成的训练样本对SVM进行学习和训练。最后输入按照最小条件属性集及相应的原始数据重新形成的测试样本集,对系统进行测试,输出预测结果。
3 算例与分析
由于上海股市起步早,数据多,大盘指数综合了各方面的因素影响,具有较强的代表性。下面用本文提出的基于粗集预处理的SVM预测系统对上证综指每日收盘指数进行预测。文中采用预测均方差(MSE)评价指标作为参考
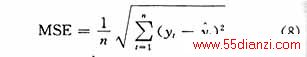
式中,yt为实际值,yt为预测值。
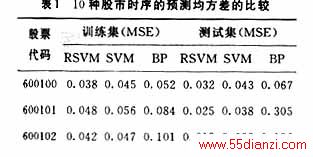
实验中共取10组股市数据,利用从1998年6月15日到1999年10月9日(481天)的股价(收盘价)时序数据为训练集来训练得到的基于粗糙集的SVM预测模型(RSVM),对2000年11月19日到2001年2月15日的股价时序作为测试集来进行预测,表1显示了本文方法与BP神经网络(BP)、标准SVM(SVM)方法预测精度的比较,表2显示了三种模型训练时间和测试时间的比较结果。其中,在RSVM和标准SVM模型中均采用高斯核函数作为支撑向量机的核函数,参数取值为σ=2.5,c=100和ε=0.001,神经网络模型采用标准的三层BP网络,隐层单元数通过试凑法选取,迭代次数为3 000次。
从表1结果比较可以看出,通过粗糙集预处理的SVM预测系统无论是训练集还是测试集预测精度都明显高于标准SVM模型和BP神经网络模型,涨跌趋势预测的准确率至少提高了8个百分点,说明了粗集预处理的有效性。从表2结果可以看出,对一般的非线性股市时序,本文方法在训练次数、训练和测试时间等方面明显优于其它两种方法。研究结果表明了本文所提模型的有效性,同时看到了RS理论和SVM算法结合在股市价格预测领域的巨大潜力。


4 结 论
在分析RS理论与SVM算法各自的优缺点基础上,本文提出一种将RS理论方法与SVM相结合的方法。通过RS理论方法可减少信息表达的属性数值,减少SVM构成系统的复杂性。结合SVM信息系统,具有较强的容错及抗干扰的能力,将RS作为前置系统,再根据RS方法预处理后的信息结构,构成SVM数据预测系统。将该系统应用于股票价格预测中,与BP神经网络及标准SVM方法相比,得到了较高的预测精度,从而表明了该系统的优越性。
参考文献:
[1] Vapnik V N.The nature ofstatisticallearning theo-ry[M].New York:Springer,1995.12~38.
[2] Pawlak Z.Rough sets[J].International JournalofInformation and Computer Science,1982,11:241~256.
[3] 曾黄麟.粗集理论及其应用(修订版)[M].重庆:重庆大学出版社,1998.15~34.
[4] 曾黄麟.基于粗集理论的神经网络[J].四川轻化工学院学报,2000,13(1):1~4.
[5] Chang Mingwei,Lin Chenjen,Weng R C.Analysisof nonstationary time series using support vectormachines[A].SVM2002,Niagara Falls[C].Canada,2002.160~170.
[6] Muller K R,Smola A J,Ratsch G,etal.Predictiontime series with support vector machines[A].Procof ICANN′97[C].Springer LNCS 1327,1997.78~92.
[7] Tay F EH,Cao Lijuan Cao.Application ofsupportvector machines in financial time series forecasting[J].Omega,2001,29(2):127~133.
[8] Shevade S K,KeerthiSS,Bhattacharyy C,et al.Improvements to SMO algorithm for SVMregression[J].IEEE Trans on Neural Networks,2000,11(5):356~362.
上一页 [1] [2]
本文关键字:暂无联系方式电力配电知识,电工技术 - 电力配电知识






