(2)迭代过程(第t次迭代的第k层)。
Step1分层更新。
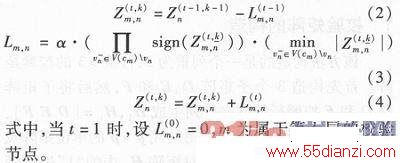
Step2译码判决。若Zj<0,则
=1,否则
=0,更新译码结果
。 (3)译码结构校验。完成一次迭代后,对更新的译码结果进行校验。若满足
xHT=0,或迭代次数达到系统设置的最大迭代次数,则停止译码,并输出译码结果。否则,跳回步骤(2)进行新一次迭代。
3 正规QC_LDPC码的译码器
3.1 译码器的结构
对码长为3 456,码率为1/2的(3,6)正规QC_LDPC码,子矩阵大小为16×16,共有108个子块行,216个子块列,648个非零子矩阵。采用分层迭代译码算法实现译码器,译码过程中只保存Zn和Lm,n两种中间数据,变量节点信息则通过式(2)计算得出,以减小数据存储量。为便于硬件实现,选择α=0.75作为修正因子,这样只需简单的带符号位右移和加法运算便可完成数据修正。由于将每一个子块行作为一个分层,因此译码器的并行度为108,即共需108个基本运算单元。对译码器中的数据进行6 bit量化,并对计算过程中产生的溢出数据采用截断处理,这样的量化处理使译码性能约有0.1 dB的损失,但节约了硬件资源。
图1为分层译码器的整体硬件结构。
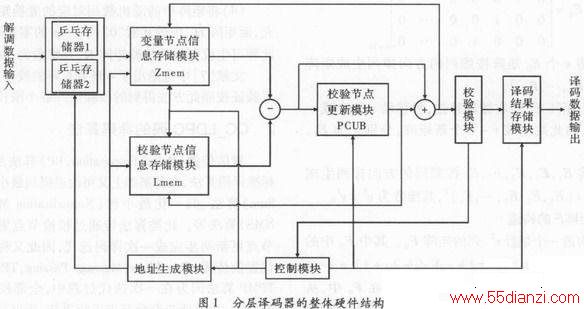
(1)数据输入模块。接收解调模块输出量化后的对数似然比数据,完成Zn的初始化。该模块采用乒乓操作,即当其中一个存储器接收数据的同时,译码器从另外一个存储器中读取数据进行译码,以此来提高译码器的吞吐量。
(2)数据存储模块。根据译码过程中所存储数据的不同,存储模块可划分为3块:1)后验概率存储模块Zmem,用于存储Zn。单个Zn的长度为6位,每个子块列对应的存储空间为6×16=96位,对应子块列数,共需216个此类模块。2)校验信息更新存储模块Lmem,用于存储,单个的长度为6位,每一行有6个非零元素,所以每行对应的存储空间为6×6=36位,而每一子块行所对应的存储空间为6×6×16=576位。对应子块行数,共需108个此类存储模块。3)译码结果存储模块,用于存储译码的结果。每一子块列对应的译码数据长度为16位,对应子块列数,共需216个此类存储空间。同样为了提高吞吐量,译码数据输出模块也采用乒乓操作,当一个存储器进行译码结果更新时,另一个存储器向外设输出存储器中的译码结果。
(3)校验节点更新模块(Parity—Check UpdateBLOCk,PCUB)。校验节点模块是译码器的核心处理单元,完成迭代的更新过程。共有108个PCUB模块进行并行处理,一次更新108组数据。每一组相关的6个变量节点信息串行输入PCUB中的FIFO寄存器,并逐次进行比较,寻找该组数据中的最小值与次最小值。当一组数据输入完成后,最小值与次最小值得以确定,再从FIFO寄存器中依次读出数据同最小值与次最小值比较,再更新数据。迭代译码过程主要被划分成两个阶段,变量节点信息输入FIFO阶段和变量节点信息输出FIFO阶段。这样的结构适合采用二级流水线,当一组已输入的变量节点信息从FIFO中读取时,将下一组变量节点信息输入FIFO。通过二级流水线处理,提高了近一倍的数据吞吐率。
(4)地址生成模块。地址生成模块中包含一个保存校验矩阵中所有子块位置和子块偏移量信息的只读寄存器(ROM)。通过从ROM中调取信息,分别产生Zmem和Lmem的读写地址。
(5)校验模块。校验模块在每一次迭代结束之后,对所有校验方程进行验证,若全部满足则停止迭代,否则进行下一次迭代过程,直至达到预先设定的最高迭代次数为止。
(6)控制模块。控制模块中设置整个译码器的状态机,控制译码器各个子模块有序运行。
3.2 译码器中内存读取的问题及改进
在PCUB模块中,每个校验节点对应的6个变量节点信息串行加入迭代过程,而这些节点信息存储在与之对应的216个Zmem中。由于校验矩阵列重为3,因此,若按照校验矩阵原来的结构,当108个PCUB并行从Zmem中读取数据时,顺序读取变量节点信息时可能从某一子块列对应的Zmem中读取1~3个数据,这样不同的读取情况,会增加Zmem的硬件设计复杂度。
由于变量节点信息加入迭代过程的先后顺序并不影响译码器的结构,因此对变量节点信息的读取顺序加以改进,将原有的读取顺序重新排列,使得在同一时刻的PCUB从不同的子块列对应的Zmem中读取数据,即每一时刻Zmem最多提供一个数据,这便大幅降低了Zmem的设计复杂度,进而提高硬件的通用性。
4 FPGA实现
选用ALTEra公司StratixIII系列的EP3SL340器件,设置最大迭代次数为5次,在QUARTusII 9.0下完成综合与布局布线,硬件资源消耗如表1所示。

在译码过程中,首先花费108个时钟进行Zmem的初始化过程,完成后开始迭代译码。在每一次迭代过程中,PCUB模块进行108次更新,由于采用流水线结构,每次更新实际仅需花费6个时钟,再加上第一组数据进入流水线花费的额外6个时钟,5次迭代共花费6×(108×5)+6=3 246个时钟。
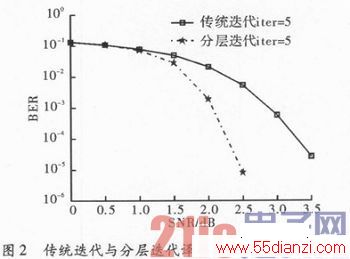
图2为传统迭代与分层迭代译码算法的性能曲线比较,为AWGN信道模式下采用BPSK调制,进行6 bit量化。通过图中的性能曲线可看出,在最大迭代次数同为5次的情况下,对正规QC_LDPC码采用分层译码器处理后相比采用传统部分并行结构译码器具有较好的译码性能表现,在信噪比为2.5 dB的情况一,误码率可以达到10-5量级。
5 结束语
文中首先利用3个不同的子矩阵分别按照指定的方法进行移位运算,组合得到无4环和6环的基阵,进而利用单位矩阵及其移位矩阵作为替换因子随机替换基阵中的“1”而扩展得到所需的校验矩阵。随后采用分层译码算法,该算法较传统的部分并行结构有较好的收敛性,并降低了迭代次数的要求。同时在Altera公司的StratixIII系列FPGA上得以实现,验证其达到了较高的译码吞吐量。
本文关键字:译码器 编、解码-加、解密电路,单元电路 - 编、解码-加、解密电路
上一篇:2位BCD输入电路






