随着 嵌入式 系统数据对象处理量的急剧增加,对 存储 碎片收集 的实时性能的要求也显得日益突出,本文介绍的真正高效、实时、确定性的两种存储碎片收集技术将对(中国)工程师提供策略上的指导。
在嵌入式系统设计过程中,Java程序员并不需要弄清楚哪些数据占用了哪些存储器或者应该在什么位置释放哪些存储空间,设计工程师只需要简单地分配对象而后由系统来释放这些资源。这样就可以完全消除悬浮指针错误,因而极大地减小存储空间浪费的可能性。由于并不需要一些显式的规则来指定这些存储空间的释放,因此简化了接口并且增强了软件复用。自动诊测并释放这些不再使用的对象的系统进程称为存储碎片收集(garbage collection)。
假如存储碎片收集真有这么好,人们也许会怀疑为什么在ANSI C++中不具备这样的功能。事实上,C++语言扩充版允许程序员将一些类型指定为“受控对象类型”,比如在MICroSOFt Visual C++的.NET平台中就能找到这种应用。这些受控对象在一定的条件下,可以实现自动存储碎片收集。问题的关键是存储碎片收集器必须能够找到所有的对象指针。由于C++允许将指针映射为其它类型,所以通常情况下无法追踪所有的指针。
关联存储碎片收集是对传统存储碎片收集算法的一个重大改进。基本的思路就是关注最新的对象。这是由于大多数对象都是很快产生而又很快消失,这些很快消失的对象集通常构成了绝大部分存储碎片。当然事情远比这要复杂。
弹性清除存储碎片
基于“标示和扫描”方式的传统存储碎片收集算法工作过程如下:当存储空间太低(下降到一个失效的新值)时,系统就会停止所有用户线程,定位无法访问的对象集合并且释放这些对象。要做到这一点就必须检查每一个对象索引,如从“根”开始的局部变量和静态类型域。检查每一个索引的对象确定其是否已经被标记过。如果没有,首先标记该对象并且对它所有的索引进行处理,否则就继续处理下一个索引。这一过程结束后,任何未被标示的对象都被认为是无法访问的对象,因而可以回收再利用其占用的存储空间。由于这种技术能够正确地检测被其它消失对象索引的成组消失对象,因而要比索引计数机制高明。图1和图2分别显示出这一对应过程前/后的图像。
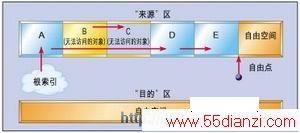
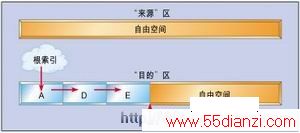
当然存储空间在任何时候都有可能出现自由空间过低的情况,并且标示和扫描过程所需要的时间正比于对象以及索引的数量,因而就会出现应用程序可能周期性地出现不响应或者滞后短暂的时间间隔才开始响应的问题。这样的滞后在实时系统甚至是在“软”实时的系统中都是不能接受的。
有的设计师试图使用一种称为增量式存储碎片收集(incremental garbage collector)的技术来确保这种应用的滞后时间最小。简单地说,就是存储碎片收集器仅仅在一个固定的时间增量上运行,运行结束之后交给用户线程一个重新执行的机会。应用程序有更多时间运行之后,增量式存储碎片收集器将从原来停止的位置处继续工作。注意:当应用程序线程先占了存储碎片收集器线程后,有的存储碎片收集器必须从头开始重新运行,这样的存储碎片收集器就称为可以被抢先的,但不是增量式的。
可以抢先式以及增量式存储碎片收集器都声称可以减少滞后时间,但是这些算法效率的差异却很大。对抢先式存储碎片收集器来说,如果经常被抢先,那么收集器线程永远无法进一步执行,因而也就没有任何的用处。同样,如果存储碎片收集只有当某一个应用线程极度缺乏存储空间时才启动执行的话,那么至少该线程(如果不是完整的应用程序)必须滞后运行,因为该线程要在存储碎片收集线程释放存储空间之后才能继续运行。
收集器时间增量的长度也称为等待时间,它对于应用的响应同样也是十分关键的。取决于应用的实现时间增量,其范围大约从几秒到几十分之一毫秒。时间增量越小,应用的响应就越具有实时性。很显然,在应用的响应速度与存储空间收集器的工作能力之间存在一种工程折衷。
一个去碎片(defragmenting)的存储碎片收集器可以在存储器空间各处移动有效对象,并且将闲置的存储器空间合并成少数更大的存储器区块。如果不具备这种去碎片的能力,那么可用的存储器空间将被分隔成许多小的存储器小块,因而最终大对象的存储空间分配可能失败(特别是在长运行时间的程序中)。
由于系统越来越难找到足够大的自由存储器空间以满足应用程序的需要,因此存储器去碎片也会导致每一次的存储空间分配操作要花更长的时间。相反,在一个已经去碎片的存储器空间中,存储空间的分配要快得多。系统只需要增值一个自由指针,这并不比为一种功能调用而分配一个堆栈结构更困难。
去碎片存储碎片收集器通常将存储空间分为几个区域。一个区域的存储碎片收集完成之后,通常将该区域中的有效对象集中到其它区域中去。这一过程结束后,原来的区域会被清空,而且目标区域中也不存在任何间隙。当然这还需要附加存储器,然后才能消除存储器碎片。
www.55dianzi.com
关联 存储 碎片收集
关联存储碎片收集(generational garbage collection)的工作方式如下:许多存储器区域被指定为存放新产生对象的特殊场所。当这些对象存在的时间变长(存活的时间变长,在存储碎片收集期间依然存活),就会将它们从这一特殊区域转移出去并且放到主存储区域。某些关联存储碎片收集算法甚至还区分几个“较早的”代。.NET平台以及C#语言的存储碎片收集器可以区分三代,所以可以将第一代与存放新产生对象的区域分别开来。为了简单起见,介绍仅有两代的情况,多代的算法与此相似,只是管理操作方面的运算更多。
关联存储碎片收集仅仅考虑新产生对象存储区域,从本质上来说,它假定所有驻留在非新产生对象存储区域的对象仍然在被引用(也就是说它们仍然是有效的)。要做到这一点,就需要有一种方法来计算所有索引了新产生对象的集合。为了加速这一过程,需要维护一个独立的“老对象到新产生对象的索引”表,这一索引表列出了所有非新产生对象对于新产生对象的索引。这一表格极大地加速了新产生对象存储区域对象的检查,与此同时非新产生对象则根本不需要检查。
也许有人会关心:开始的时候如何追踪非新产生对象对新产生对象的索引?答案在于一种称为“写屏蔽”技术。写屏蔽监视所有的存储操作,并且不断查询“正在存储的对象索引了非新产生的对象吗”?如果是这样,接下来就会询问是否将正在被写的旧值以及/或正在被存储的新值进行了索引,并产生了新的对象。此外,还要对这一组老对象到新产生对象的索引进行相关的刷新。请注意:通过比较索引的地址与新产生对象存储区域的边界地址,存储碎片收集器可以迅速地判定一个索引是否指向了一个新产生的对象。
典型应用的实际测试表明:老对象到新产生对象的索引集合通常都比较小。测试也证实关联存储碎片收集可以线性地分配空间收集工作。也就是说,关联存储碎片收集在大约八分之一全部存储碎片收集的时间里可以收集到最新的第八个存储器空间。这将释放比八分之一存储碎片要多得多的空间。
图3显示了存储碎片收集之前的一种情况。新产生对象存储空间包含三个对象:C、D和E。对象C包含到对象E的索引。主要存储器区域包含两个对象:A和B。对象A包含到对象C的索引。这一个索引被记录在“老对象到新产生对象”的集合中。根索引集合包含到A和E的索引。
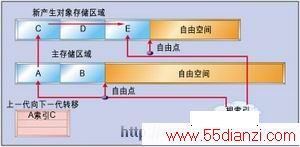
这个实例显示了对新产生对象存储区域同时进行存储碎片收集和去碎片的情况。同时也显示了对新产生对象存储区域进行存储碎片收集并且直接收集到主存储空间中的情况。这样可以提升新产生对象存储区域中的所有对象。也就是说,这些对象下一轮的关联存储碎片收集过程中将不再被检查。如果算法支持几代关联存储碎片收集过程,那么就需要通过存储器去碎片技术整合到一个区域并且进行更高一代关联存储碎片收集。
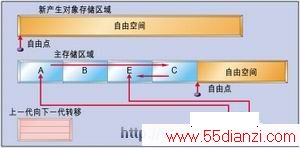
在关联存储碎片收集过程中,根到A的索引将被忽略,但是根到E的索引将把E标示为有效,所以在目标区域中会创建E的一个副本,并且刷新C到E的索引。
E不包括任何索引,因而对E不作任何处理。老对象到新产生对象的集合也需要检查,在检查中会发现A到C的索引。C会被标示为有效,所以在目标区域中就会创建C的一个副本,并且刷新从A到C的索引。对象C包含一个到E的索引。由于E已经被复制,C中的索引被刷新,但是无需再复制E。而无法访问的对象D则不会被复制,因此该区域重新整理时D就会被删除。这样就会产生图4中显示出的结果。
本文关键字:嵌入式 嵌入式系统-技术,单片机-工控设备 - 嵌入式系统-技术
上一篇:嵌入式系统支柱学科的交叉与融合






