case UGL_FONT_ SLANT_ANGLE _GET:(*(UGL_SIZE *)pInfo) = pFT2Font->italicsize;
status = UGL_STATUS_OK;break;
4) 在ft2DrawStringImageCache 函数中,增加矢量字体在斜体时的矩阵值;增加矢量字体在粗、斜体时字体位图索引的获取。因为矢量字体在粗、斜体时矩阵值和位图索引号的获取和正体有些差异,所以在处理时需和正体分开处理。
5) 在ft2DrawStringSmallBitmaps 函数中,增加矢量字体在斜体时的矩阵值;因为矢量字体在粗、斜体时使用ft2GetGlyphIndex 函数不能正确获取位图索引,修改为FT_Get_Char_Index 来获取位图索引;增加在粗、斜体时的矢量字体位图的处理。
uglfont2.c 修改代码如下:
修改uglConstructFontDef 函数,增加斜体信息赋值,pFontDefinition->italic = pFontDescriptor-> italic.
去除语句pFontDefinition->weight = (pListArray[matchIndex].fontDesc.weight.min + pListArray[matchIndex].fontDesc.weight.max)/2;,使用语句pFontDefinition->weight = (pFontDescriptor-> weight.min +pFontDescriptor->weight.max)/2;替换。
4 结论
矢量字库已应用于嵌入式浏览器、嵌入式阅读器等多个软件开发项目,实际工程应用表明,矢量字体的切换速度、显示速度都能满足应用要求,并且字体大小的无级缩放、粗斜体显示、以及旋转显示等效果能使人机界面更加友好,使用更加便捷。
字符编码根据长度分为单字节和双字节两种编码方式,单字节编码包括英文字母、数字和特殊字符等,双字节编码包括汉字和自定义字符等。
WindML 字体显示分双字节显示和单字节显示两种方式,双字节显示是两个字节作为字体编码对字库进行查询,找到字符位图并显示;单字节显示是单个字节作为字体编码对字库进行查询,找到字符位图并显示。当英文字符显示时,可以使用单字节显示或双字节显示,当中文字符显示或中英文混合字符显示时必须使用双字节显示。
VxWorks 下字体采用GB2312 编码,中文字符编码的每个字节都大于0x80,英文字符编码都小于0x80,在进行双字节显示时,需要将单字节字符转换成双字节字符。在字符转换时,先获取整个字符串长度,再判断每个字节是否大于0x80,如果小于0x80,则将单字节扩展成双字节;如果大于0x80,则将这个字节与后个字节组合成一个双字节;计算双字节数并返回,如上图2 所示。
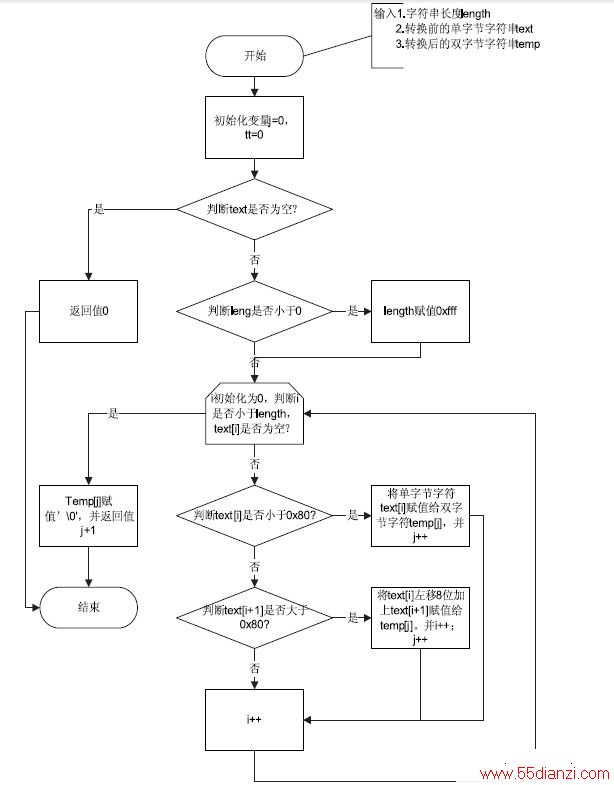
图2 单字节字符转换成双字节字符。
3.3 字体编码转换
VxWorks5.5 下汉字采用GB2312 编码, 而FreeType 在处理汉字时只能识别UNICode 编码,在处理汉字前需要将GB2312 编码先转换成Unicode 编码,GB2312 与Unicode 的编码转换表采用二维数组保存数据,共有7000 多组对应项,如果采用遍历数组的方式来进行编码转换,那么平均每个汉字编码转换需要做3000 多次的编码比较,这非常影响汉字的处理速度。
为了提高编码转换的处理速度,编码转换时采用折半查找方式来实现,使用折半查找需要先将GB2312编码从小到大排列,每个GB2312 编码对应一个Unicode 编码。在使用折半查找时,先取first=0 end=数组长度,然后(first+end)/2 得到一个中间编号,再通过中间编号获取相应的GB2312 编码和显示汉字编码比较大小,如果中间值大,则将first=0 end=中间编码组合再进行折半查找;如果中间值小,则将first=中间编码 end=数组长度 组合再进行折半查找;如果相等,则将GB2312 编码对应的Unicode 编码提交程序处理。
使用折半查找一个汉字最多只需查找13 次,大大提高了汉字Unicode 编码的查找速度,加速了汉字显示。
本文关键字:暂无联系方式嵌入式系统-技术,单片机-工控设备 - 嵌入式系统-技术
上一篇:微内核的结构分析






