为了解决这一问题,我们采用了分档方案,即将外部 SRAM 分区为 bin,每个 bin 都可包含固定数量的配置文件词。Bin 的大小决定了可处理的冲突数。如需给 bin 分配配置文件词,只需将词 ID 的较下部分作为存储器地址,从而避免了实际的散列操作。
www.55dianzi.com
让 SRAM 存储器容量设定为 NM 配置文件词。词 ID 是一个无符号的整数,其范围取决于词汇量,就我们的例子而言约为 400 万个词,需要 24 位。词加权为 8.32 定点数,因而配置文件词需要 64 位。RC100 上的 SRAM 包括 4 个 16 MB 存储库,因此 NM="223"。Bins 的数量 nb="NM/b" 和 bin 地址用词 ID“t”进行计算,即 (t&(nb-1)).b。
Bin 的占用概率 x 由组合决定,置换决定 bin 的数量 nb 和描述词的数量 np。这样,我们就能计算 bin 溢出的概率就是 bin 大小的函数(即 bin 的数量),即 NM="b".nb。bin 尺寸越大,查询就越慢,但是,由于 SRAM 存储库包括 4 个独立的 64 位可寻址双端口 SRAM,我们实际上可以并行查询四个配置文件词。因此,相对性能会降低 1/ceil(b/4)。我们的分析结果显示,即便对最大型的配置文件来说(16K,我们研究所用的最大配置文件为 12K,不过通常配置文件比这都要小得多),b=4时(最佳性能),bin 溢出概率为 10-9。换言之,描述词被丢弃的概率不到 10 亿分之一。应注意的是,由于我们假定词汇量无限大,因而这一估算还是保守数字。
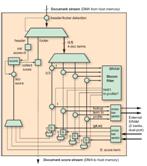
图 3 ―― 过滤应用的 FPGA 实施示意图
通过将文档表述为“词袋”,文档流就是文档 ID、文档词对组 (document term pair set) 等对列表。从物理上说,FPGA 以每秒 1.6 GB 的速度从 NUMAlin 接受 128 位字流。因此,文档流必须在字流上编码。可将文档词对 di =(ti,fi) 编码为 32 位:24 位用于词 ID(支持 1,600 万个词的词汇库),8 位用于词的频率。这样,我们就能将 4 个对组合到 128 位字中。要标示文档的起点与终点,我们需要插入包含文档 ID(64 位)和标志符(64 位)的报头与脚注字 (footer word)。
如上所述采用查询表架构和文档流格式,实际的查询和评分系统(图 3)会非常直接。我们只需扫描输入流以检查报头和脚注字即可。报头字将文档得分设为 0,而脚注字则收集并输出文档得分。对于文档中的每四个配置文件词,Bloom 过滤器首先丢弃否定词结果,再从 SRAM 读取四个配置文件词。并行计算并添加(图 4)每个词的得分。实际上,四分之三的配置文件词 ID 不会匹配于文档词 ID;只对第四个进行实际计算。将文档中所有词的得分进行累加,最后得分流在输出到主机存储器之前与限值进行比较过滤。
主机―FPGA 接口将文档流从存储器缓冲器中传输至 FPGA,并将得分流返回至客户端中。一旦从客户端接收到配置文档 ID 表,子进程即从主进程中分叉出来,以构建实际的配置文件,将其载入 SRAM 并在 FPGA 上运行算法。每个子进程都会产生一个独立的输出线程,以对从 FPGA 获得的得分进行缓冲,并通过 TCP/IP 将这些得分传输到客户端,从而使用网络对得分流进行多路复用。若没有该线程,网络吞吐量的波动就会降低系统性能。这种主机接口架构的主要优势在于,它具有很高的可扩展性,能轻松满足大量 FPGA 的需求。
大幅度提速
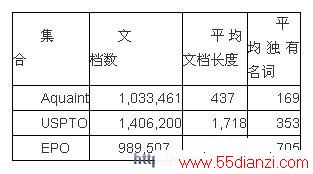
为了评估 FPGA 加速型过滤应用的性能,我们进行了一系列实验,将基于 FPGA 的实施方案与采用 C++ 编写的运行于 Altix 之上的优化参考实施方案进行了比较。在比较过程中,我们使用了三个 IR 测试集合(参见表 1):一个是文本检索会议 (TREC) 提供的基准参考集合 TREC Aquaint,还有两个分别是美国专利与商标署 (USPTO) 和欧洲专利署 (EPO) 提供的专利集合。我们选择上述测试集合来评估不同文档长度和大小对过滤时间的影响。
表 1――集合统计
为了仿真众多不同的过滤器,我们通过选择随机文档并用标题作为请求,随后再选择请求服务器返回的固定数量的文档作为伪相关文档,来为每个测试集合构建配置文件。我们接下来使用返回的文档构建相关性模型,该模型定义了文档集合中每个文档应当匹配(就好像从网络进行流处理一样)的配置文件。配置文件中的文档数量从 1 到 50 不等,可确定增加配置文件的大小(词数和文档数)会对性能有何影响。我们将上述进程重复 30 次,并计算平均处理时间。
我们在表 2 和图 5 中对有关结果进行了总结。从表中可以清晰地看出,FPGA 实施方案在速度方面通常比标准实施方案快一个数量级。从图中可以看出,配置文件大小(需要匹配的词数)增加后,标准实施方案变得越来越慢,而 FPGA 实施方案的速度相对保持不变。这是因为 FPGA 实施方案支持配置文件评分的流分线操作,这样无论配置文件大小如何,时延基本保持不变。
www.55dianzi.com
这些结果清晰表明,FPGA 对加速 IR任务有着巨大的潜力。FPGA 的提速幅度已然相当大(特别对大型配置文件而言尤其明显),而且仍有进一步提高的空间。通过仿真,我们确认 FPGA 算法给一个文档词评分需要两个时钟周期。制约因素为每周期 128 位的 SRAM 存取速度,这需要两个周期才能读取四个配置文件词。如果时钟速度为 100 MHz,则意味着 FPGA 能在 15 秒之内完成整个 EPO 文档集合的评分。当前应用在四个 FPGA 上需要约 8.5 秒,因此原则上我们至少可以让性能再翻一番。
差异的原因在于 I/O 流 (streaming I/O):通过主机操作系统设备驱动器可将文档流从用户存储器空间传输至 NUMAlink,这需要直接存储器存取 (DMA) 传输。驱动器可传输流的缓存模块。目前,对所传输模块的大小来说,这一传输并不是以最优的方式实施的,进而导致无法达到最高吞吐量。此外,用独立的线程进行传输排序也能避免传输时延。
遇到的问题和吸取的经验
这一项目的意义不仅在于它展示了 FPGA 作为信息检索任务加速器的优势,而且还为我们提供了 FPGA 加速系统软硬件要求的重要信息。
至主机系统的 I/O 是确保性能的关键:NUMA 存储器与 FPGA 之间的 DMA 机制必须获得 MitrionICs SDK 和 SGI RASClib 的支持。在此前的项目中,我们必须先将数据传输到电路板上的 SRAM 中才能进行处理,但这会严重影响性能,因为数据的载入和结果的卸载会造成非常大的开销。此外,我们也清晰地认识到,IR 任务尤其需要大量的片上和板上存储器,才能实现效率最大化。
此外,为了充分使用 FPGA,未来的平台必须具备两个重要特性,一是必需能在 FPGA 之间直接传输数据,二是必需能够关闭主机处理器(或用一个主机处理器控制多个 FPGA)。关闭主机处理器的功能尤其重要:在 Altix 平台上,即便 Itanium 处理器完全处于空闲状态也不能关闭。但是,空闲的 Itanium 处理器的功耗也高达工作状态下所需功耗的 90%。因此,尽管 FPGA 加速的节能效果明显,但我们目前的系统即便在加速器运行过程中主机存储器空闲状态下,其总体节能作用仍然有限。
开发 FPGA 加速型系统的另一重要领域就是软件。我们的经验明确反映出,主要的复杂问题在于FPGA 和主机系统之间的接口连接:Mitrion-C 中的实际 FPGA 应用开发效率非常高;采用 Lemur 工具套件构建查询和服务文档的框架也相对容易开发。但是,采用 RASClib 开发连接主机应用和FPGA 接口的代码非常复杂,而且由于并发性问题,还非常难以调试。因而,接口代码的开发占据了绝大部分的开发时间。
表 2 ―― 性能统计数据
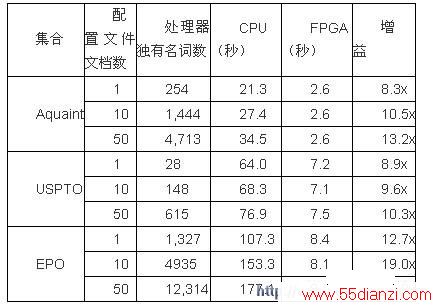
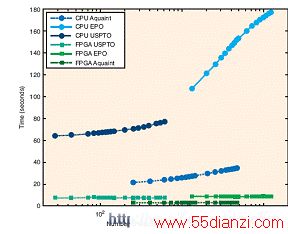
图 5 ―― 时间(秒)和配置文件中文档数量的对比图
FPGA 高级编程的最后一个问题是编译速度。习惯于 C++ 或 Java 等语言的开发人员认为即便应用非常复杂,构建时间也应该比较短。除了最基本的设计之外,当前的 FPGA 工具执行综合以及放置路由工作几乎都需要一整天的时间。非常长的构建时间会严重影响工作效率,因而时间应当缩短到一般性软件构建时间,这样才能使 FPGA 加速更具吸引力。
定制硬件平台
我们用这个项目探讨了 FPGA 加速的可能性,并展示了 FPGA 作为数据中心绿色环保技术的巨大潜力。我们希望进一步扩展这项研究,调查文档处理所需的全系列工作任务,如语法分析、词干、索引、搜索以及过滤等。我们清楚地认识到,现有系统在节能潜力方面很有限,我们希望研究能以业界最高效率专门执行信息检索任务的可定制硬件平台。这样,我们就能显著加速算法的执行,同时大幅度降低能耗,从而开发出更加环保、速度更快的数据中心。
www.55dianzi.com
本文关键字:技术 DSP/FPGA技术,单片机-工控设备 - DSP/FPGA技术






