下面以4×4矩阵逆整数变换函数itrans和1/4像素插值滤波get_bLOCk(),说明用汇编指令优化带来的性能提高。4×4矩阵的逆整数变换函数itrans采用的是2级蝶形运算,先对4×4矩阵的每一行分别做行逆变换,再对每一列做列逆变换。一维变换采用如图2所示的蝶形算法。
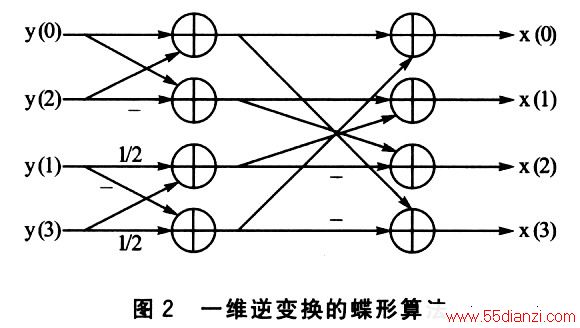
Blackfin处理器的SIMD结构支持向量操作,最多可以在1个周期内完成4个16位的加法操作。它的并行指令能同时进行算术运算和两个数据的装载/存储操作。例如上述的蝶形运算可以用如下指令实现(设寄存器IO中保存了输人数据y[4][4]的地址,I2中保存了系数数组cof[2]={0x7fff,0x4000}的地址,Il中保存了临时变量tmp[4][4]的地址,R2和R1保存的是中问结果):
R7=[IO++];
Al=R6.I*R7.1,AO=R6.1*R7.1(IS)┃│I R5=
[10++]┃┃[││++]=R2;
R4.h =(A1一一R5.1*R6.1),R4.1=(AO+=R5.1*R6.1)(IS)││W[I1++]=R1.h;
R7.1=R6.1*R5.h(IS)1 W[11++]=R1.1;
R5=R7>>>1(v);
A1=R6.1*R5.h,AO―R6.1*R5.1(IS);
R3.h一(A1+一R6.1*R7.1), R3.1一(AO =R6.1*R7.h)(IS);
R2=R4+l+R3,R1=R4一│ 一R3:
完成一次一维逆变换只需8条指令,算上函数调用的开销和其他一些辅助指令,完成一个4×4矩阵的逆整数变换时总共需要82条指令周期。表1是优化前、后的比较。

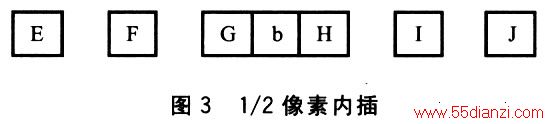
get_block函数对像素矩阵进行1/4像素插值操作。先用六阶滤波器进行1/2像素插值,然后用线性内插法进行l/4像素插值。
l/2像素b计算方法为:b=round((E一5F+20G+20H一5I+j)/32)。示意图如图3所示。E、F、G、H、I、J是整数像素,b是G和H之问的1/2像素。
4 实验结果
在EZKit533开发板上测试了解码器算法,对CIF格式(352×288)的foreman测试序列,可以达到45~50帧/s的解码速度;对CIF格式的mobile测试序列,能够达到40帧~44帧的解码速度。如果增加解码速率控制模块,可以稳定地实现以30帧/s的速率播放CIF测试序列。实验结果证明,在Blackiln处理器上实现H.264实时解码器是可行的。ADI公司甚至声称可以在600 Mtz的BF533处理器上实现D1(720×576)格式的视频实时解码器。
BIackfin处理器有低功耗、低成本和高性能的特点。在Blackfin处理器上实现的H.264视频解码器很适合用于IP机顶盒、可视电话、PMP(便携式媒体播放器)等嵌人式视频应用中。






